
The body of a reflex scanner source file consists of one or more named scanner modes. A scanner mode is composed of one or more rules. A rule is a regular expression with associated handler code. Essentially each scanner mode is a separate state machine, as it is impossible to transition from anywhere in one scanner mode to a different scanner mode without an explicit transition in the rule handler code. Each rule regex in a given scanner mode is essentially a separate branch in a massively alternated regex.
TODO: graph of AST produced by the example
Here is the NFA produced from the example reflex source given in Format Of The Reflex Source File.
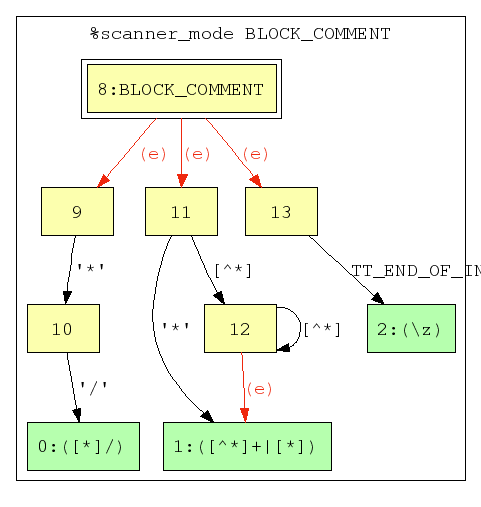
Notice that the two scanner modes are entirely separate NFAs. Also notice that though there is only one start state (the double-lined graph nodes) for each scanner mode, there are multiple accept states (the green graph nodes). This is because not only does the scanner need to decide wether or not the input is accepted by any of the regexes in the scanner mode, but it has to determine which one(s) accept the input. However, notice that there is only one accept state for each regex. This fact will be contrasted after DFA generation.
In order to construct the DFA from which to generate the scanner targets, we will use the modified subset construction algorithm on each separate scanner mode's NFA. The result is an equal number of DFAs, each corresponding to the NFA it was generated from. Here are the DFAs corresponding to the above NFAs.
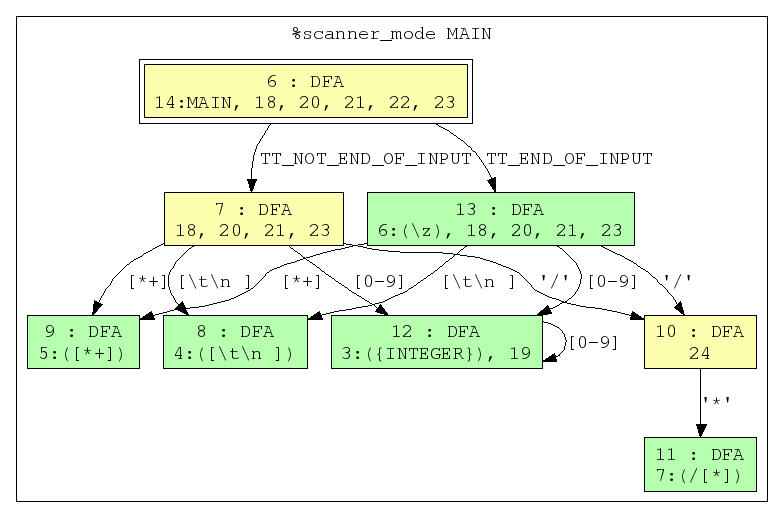
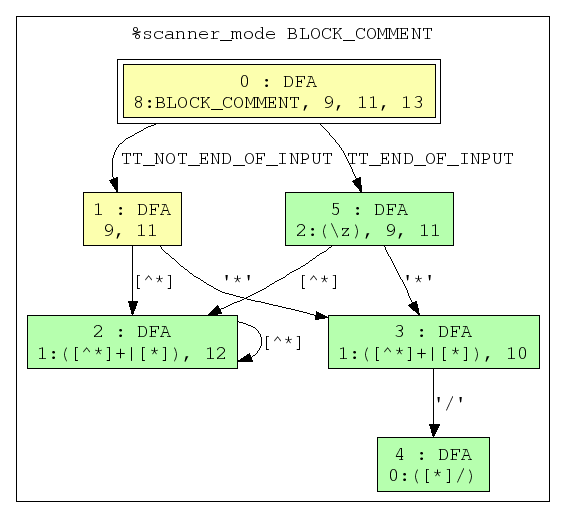
Because each DFA state is a set of NFA states, each node is labeled first with the DFA state index, then the list of NFA states it corresponds to. Again, start states are indicated by double-lined graph nodes and accept states are indicated by green graph nodes. For the DFA states which contain accept states from the NFA, the accepting regex is indicated after the state index, separated by a colon (just like in the NFA graph). If a DFA state contains an accept state from the NFA, it is also an accept state. Notice that in the DFA graph for %scanner_mode BLOCK_COMMENT there are two DFA states which contain the NFA state 1:([^*]+|[*]). This is a result of the subset construction algorithm. Another result is that over all states in a DFA, the corresponding NFA state set is unique.
If a DFA state contains more than one NFA accept state, the state with the lower index (i.e. declared first in the reflex source file) takes priority, as only one rule handler can be be executed for each string that is accepted.
The goal of this section is to enumerate the concepts and algorithms necessary to implement a target using whatever crappy language your heart desires. What will be implemented is a machine which runs the FA generated by reflex (both an NFA and equivalent DFA are generated), and it must conform to certain standards and obey certain rules to provide consistent behavior across all targets.
First, you must gain an understanding of exactly what a scanner does. The scanner simply analyzes input, one character at a time, attempting to accept the longest string which satisfies its FA. Once the scanner can make no valid transitions based on the next input atom, it executes the code associated with the most recently encountered accept state(s). Assuming the executed code didn't cause the scanning to halt, the machine sets the current state to the starting state for the current scanner mode (e.g. for %scanner_mode MAIN in the above example, DFA state 6) and continues processing.
The main parts of a scanner, as defined in this document, are:
The input and automaton apparati are essentially unchangeable, to be used as common code to all customized scanner apparati (e.g. the input and automaton apparati could be implemented as base classes for each of many possible customized scanner apparati to subclass). The following is an example class hierarchy chart to illustrate the point.

Because all of the customized scanner apparati (MapFileScanner, NetworkCommandScanner, and ArithmeticScanner) use AutomatonApparatus and InputApparatus as their base classes, there must be no scanner-specific customization in either. Specifically, this means that the codespec files which specify the input and automaton apparati must not use any of the scanner-specific codespec macros.
An atom is one piece of input, in this case an ASCII character. It can be anything in the range 0-255 (though 0 is reserved to represent beginning-of-input and end-of-input).
A deque (double-ended queue) is a well-known abstract container type. It provides random access to indexed elements (like an array), and (amortized) constant-time insertion and removal of elements (hence the double-ended qualifier). It must also provide an accessor for its length. In the context of this scanner algorithm, a deque will contain elements of type atom.
The scanner uses the input buffer (which utilizes a deque) to track the accepted text and unread text. Each index of the input buffer will be referred to as a cursor. As will become apparent soon, a cursor is only valid if it has index greater than 0. The input buffer is split into four sections.
To illustrate the input buffer graphically:
previous accepted unaccepted unread
atom string string string
ABBBBBBBBBBBBCCCCCCCCCCCCDDDDDDDDDD
^ ^ ^ ^
| | | |
index accept read length
1 cursor cursor of
buffer
The accepted string (BBBBBBBBBBBB) and the unaccepted string (CCCCCCCCCCCC) may both independently have length 0.
When first constructing the input buffer, the value '\0' (null-terminating char) should be added as the very first element (index 0). This value for the previous atom indicates the beginning of input. As more atoms are read, the end of input will eventually be encountered. Once this happens, the value '\0' should be added to the end of the input buffer, at which point, no more atoms may be read. This final atom indicates the end of input. Correspondingly, any normal atom (not the beginning or end of input) must not be '\0'.
A conditional is a pair of bitfields -- a mask and a set of flags -- which indicate a set of conditions. The mask indicates which bits are active in the conditional, while the flags indicate the values of the active bits. Each bit corresponds to a different condition at the read cursor. The conditions and corresponding bitfield values are as follows. In the following pseudocode, the existence of the previous atom is shown to be necessary (by the subtraction of 1 within the array index expression)
input_buffer[read_cursor-1] == '\\0'
input_buffer[read_cursor] == '\\0'
input_buffer[read_cursor-1] == '\\0' || input_buffer[read_cursor-1] == '\n'
input_buffer[read_cursor] == '\\0' || input_buffer[read_cursor] == '\n'
IsWordChar(input_buffer[read_cursor-1]) != IsWordChar(input_buffer[read_cursor])
The current conditional flags is the flags portion of a conditional, indicating the conditions active in the input buffer at the read cursor. The existence of the previous atom is solely to guarantee that there is always at least one atom before the read cursor upon which to perform the calculation of the current conditional flags.
The above definitions have been made for use in the following definition.
interface InputApparatus {
// types
// An 8-bit (unsigned) integer value to store atoms.
type Atom;
// An integer large enough to store the highest conditional bit flag.
type Bitfield;
// A string of atoms.
type String;
// A type which can be used to call a method taking no arguments, returning a Boolean (e.g. a C++ method pointer).
type MethodReturningBoolean;
// A type which can be used to call a method taking no arguments, returning an Atom (e.g. a C++ method pointer).
type MethodReturningAtom;
// A type satisfying the definition of input buffer, given above.
type InputBuffer;
// An integer large enough to store an index into the input buffer.
type BufferIndex;
// compile-time constants
Bitfield BEGINNING_OF_INPUT = (1 << 0);
Bitfield END_OF_INPUT = (1 << 1);
Bitfield BEGINNING_OF_LINE = (1 << 2);
Bitfield END_OF_LINE = (1 << 3);
Bitfield WORD_BOUNDARY = (1 << 4);
// members
// The deque-object which will store the read-in atoms.
member InputBuffer m_input_buffer;
// The index of the read cursor in the input buffer, as described above.
member BufferIndex m_read_cursor;
// The index of the accept cursor in the input buffer, as described above.
member BufferIndex m_accept_cursor;
// The cached value of the conditional flags at the location in the input buffer
// indicated by the read cursor. Because it is a cached value, it will have to
// be updated before being accessed at certain times.
member Bitfield m_current_conditional_flags;
// The method to call to determine if we're at the end of the input stream.
member MethodReturningBoolean m_is_at_end_of_input_method;
// The method to call to retrieve the next atom from the input stream.
member MethodReturningAtom m_read_next_atom_method;
// methods
// Should be called once and only once upon creation of this input apparatus -- one-time
// initializations including construction of all members.
void Construct (MethodReturningBoolean is_at_end_of_input_method, MethodReturningAtom read_next_atom_method);
// Should be called when this object is going bye-bye. Destroys all member variables
// and performs any other necessary clean-up.
void Destroy ();
// Return true if and only if CurrentConditionalFlags() indicates that the end-of-input
// condition is true.
Boolean IsAtEndOfInput ();
// Returns the conditional flags for the current value of the read cursor and input buffer.
// This method will first have to ensure that at least one atom on either side of the
// current read cursor is available before performing the calculations.
Bitfield CurrentConditionalFlags ();
// Returns true if and only if no relevant bits (the bits set in conditional_mask) differ
// between conditional_flags and CurrentConditionalFlags(). Using C-language operators,
// this can be calculated as
// ((conditional_flags ^ CurrentConditionalFlags()) & conditional_mask) == 0
Boolean IsConditionalMet (Bitfield conditional_mask, Bitfield conditional_flags);
// Ensures there is at least one atom in the input buffer after the read cursor, by
// using the is_at_end_of_input_method and read_next_atom_method methods (passed into
// Construct) as necessary.
Atom InputAtom ();
// Increments the read cursor by one. The read cursor should be greater than zero and
// less than the length of the input buffer.
void AdvanceReadCursor ();
// Assigns the read cursor's value to the accept cursor.
void SetAcceptCursor ();
// Extracts and returns the accepted string; the string of input buffer atoms in the range
// [1, accept cursor) -- if the accept cursor is 0, it is an error. Pops the same number
// of atoms off the front of the input buffer. Sets the read cursor to 1 (indicating the
// new beginning of the unread string). Sets the accept cursor to 0 (indicating the
// non-existence of the accept string). A result of the popping is that the new previous
// atom is the last atom in the accepted string.
String Accept ();
// Extracts and returns the atom at index 1 in the input buffer. If the accept cursor
// is not 0, it is an error. If the extracted atom is not 0 (null-terminating character),
// pops the front of the input buffer once. Sets the read cursor to 1 (which is the new
// beginning of the unread string).
Atom Reject ();
// Clears the input buffer. Pushes an atom with value 0 onto the input buffer (at this
// point, a single atom with value 0 should be the only contents of the input buffer).
// Sets the read cursor to 1 (indicating the beginning of the unread string). Sets the
// accept cursor to 0 (indicating the non-existence of the accept string). Must somehow
// indicate that the current conditional flags have not been calculated (so that when
// CurrentConditionalFlags is called, the current conditional flags can be calculated).
// This method must be called to initialize the input buffer before being used, as well
// as any time this input buffer is being reused for a new input source (e.g. reading
// from a second, different file).
void ResetForNewInput ();
}
All of the following two definitions are independent of the input apparatus -- they are definitions for the components required to run the FA generated by reflex.
The current scanner mode (not to be confused with an FA state) is the currently active "mode" of the scanner -- the two scanner modes in the example from Format Of The Reflex Source File are MAIN and BLOCK_COMMENT. Each has an associated FA -- a set of states, transitions, a starting state, and a set of accept states.
A state identifier is an abstract indicator for a single state in an FA. It can be invalid (i.e. indicating no real FA state), and its validity must be detectable. A state identifier could be implemented as a pointer to a memory address (in which case the invalid value would be NULL), the FA state index (the invalid value could be one higher than the highest valid FA state index), or whatever.
The above definitions have been made for use in the following definition.
accept_handler_index -- an index into the table of accept handlers which are provided by reflex. If this value is greater or equal to the total number of accept handlers (from all scanner modes), then it is invalid. This type must be large enough to hold the total number of accept handlers. state_identifier -- a type satisfying the above definition of a state identifier. dfa_state -- is a compound, implementing the concept of an FA state, containing: accept_index -- of type accept_handler_index. If it is a valid accept_handler_index value, then this state is an accept state. If invalid, this state is not an accept state. transitions -- a set whose elements are of type dfa_transition (described below). This is the set of all transitions from this state to others. For any given state, all transitions will either be atomic (i.e. of type TT_INPUT_ATOM or TT_INPUT_ATOM_RANGE, explained below) or conditional (i.e. of type TT_CONDITIONAL, explained below). dfa_transition -- is a compound, implementing the concept of an FA transition, containing: target_dfa_state -- of type state identifier. This is the dfa_state which will become the new current state should this transition be exercised. data_0 -- of a type capable of storing the integer values 0 through 255, inclusive. The use of this member will be explained shortly. data_1 -- of a type capable of storing the integer values 0 through 255, inclusive. The use of this member will be explained shortly. transition_type -- of a type capable of storing the integer values 0, 1, 2 and 3. This value represents what type of FA transition this dfa_transition is. The types are enumerated by reflex as follows: TT_INPUT_ATOM = 0 -- indicates that data_0 contains the ASCII value (1 through 255, inclusive) of the single atom which this transition may be exercised upon. TT_INPUT_ATOM_RANGE = 1 -- indicates the range [data_0, data_1] (inclusive on both ends) of contiguous ASCII values (1 through 255, inclusive) of atoms which this transition may be exercised upon. If the dfa_transition's type is TT_INPUT_ATOM_RANGE, data_0 will be less than data_1. TT_CONDITIONAL = 2 -- indicates that data_0 and data_1 contain the mask and flags, respectively, of a conditional. A dfa_transition of this type may only be exercised when the input buffer's current conditional flags are accepted by conditional defined by data_0 and data_1. Calculating wether or not a set of conditional flags are accepted by a conditional will be explained below. TT_EPSILON = 3 -- indicates that this is an epsilon-transition and may be exercised without consuming any input. It is ONLY used in NFAs, and so will NEVER appear in a DFA.
AcceptsInputAtom (atom input_atom) returns boolean -- indicates if the given input_atom (of the input apparatus' atom type) is accepted by this dfa_transition. AcceptsConditionalFlags (bitfield conditional_flags) returns boolean -- indicates if the given conditional_flags are accepted by this dfa_transition. Returns true if and only if no relevant bits (the bits set in data_0) differ between conditional_flags and data_1. The C-language expression to calculate this is: return ((conditional_flags ^ data_1) & data_0) == 0;
accept_handler_count -- of type accept_handler_index. This stores the number of accept handlers, and indicates the least invalid value for members of type accept_handler_index. initial_state -- of type state identifier. Stores the starting state for the current scanner mode. Its value is used to initialize current_state (see below). It must never be invalid. current_state -- of type state identifier. Indicates the current state (as described in Definitions) in the running FA. accept_state -- of type state identifier. Indicates the FA accept state which was most recently encountered (i.e. the most recent value of the current state which was an FA accept state). It is always initialized as invalid. input_buffer -- of a type implementing the input apparatus interface.
Construct (accept_handler_index accept_handler_count, method_returning_boolean is_at_end_of_input_method, method_returning_atom read_next_atom_method) -- Should be called once and only once upon creation of this automaton apparatus. Passes the values is_at_end_of_input_method and read_next_atom_method into input_buffer.Construct(). Assigns the value of accept_handler_count using the passed-in value. ResetForNewInput() can be called for pedantic safety, but in theory this is not necessary, as it will be called by the ResetForNewInput() method of the scanner apparatus (which is defined below). ResetForNewInput (state_identifier initial_state) -- calls input_buffer.ResetForNewInput(), assigns the indicated value to initial_state, and sets current_state and accept_state to invalid. RunDfa () returns accept_handler_index, string -- runs the FA as long as it can go; until the FA has no more transitions. The resulting value of accept_state will indicate if any accept state was encountered, and if so, which one. The return values are:
ensure initial_state is valid; // i.e. assert
current_state = initial_state;
ensure accept_state is invalid; // i.e. assert
while (current_state is valid)
{
if (the current state is an accept state)
{
// save the accept state and set the accept cursor
accept_state = current_state;
input_buffer.SetAcceptCursor();
}
// exercise a single transition, setting current_state to the
// transitioned-to state. if no transition is possible, make
// current_state invalid.
current_state = ProcessInputAtom();
}
if (accept_state is valid)
{
// record which rule handler for the scanner to run
accepted_index = accept_state.accept_index;
// extract the accepted string from the input buffer
accepted_string = input_buffer.Accept();
// clear the accept state for next time around
accept_state = invalid;
// return the calculated values
return accepted_index, accepted_string;
}
else // input went unaccepted
{
// extract the first unaccepted atom
rejected_string = input_buffer.Reject();
// return the calculated values; no accepted state, so the returned
// accept_handler_index is invalid.
return invalid, rejected_string;
}
ProcessInputAtom () returns state_identifier -- from the current state, this exercises the single matching dfa_transition if it exists and returns its target_dfa_state, or if no transition is possible it returns an invalid state_identifier. Remember, as noted above, a transition can only be atomic (i.e. of type TT_INPUT_ATOM or TT_INPUT_ATOM_RANGE) or conditional (i.e. of type TT_CONDITIONAL). The following pseudocode describes this method.
ensure current_state is valid; // i.e. assert
// iterate through the current state's transitions, exercising the first
// acceptable one and returning its target_dfa_state.
for (transition in current_state.transitions)
{
if (transition is atomic)
{
if (transition.AcceptsInputAtom(input_buffer.InputAtom()))
{
input_buffer.AdvanceReadCursor();
return transition.target_dfa_state;
}
}
else if (transition.AcceptsConditionalFlags_(input_buffer.CurrentConditionalFlags()))
return transition.target_dfa_state;
}
// if we reached here, no transition was possible
return invalid state_identifier;
The scanner apparatus is the main interface and is publicly accessible to the user's code. The API defined here defines the canonical behavior which all implemented reflex targets should follow (though there certainly is no absolute requirement to do so). This conformance is intended to provide consistent behavior and semantics between different targets.
Each apparatus, in hiding its subordinate, provides a much cleaner and simpler API. The scanner apparatus API is the simplest of all. The previously defined input and FA apparati have been separated out for the following three reasons.
TODO: describe the "debug spew" and "scanner mode" properties. There are two important properties of the scanner apparatus which will now be described. Firstly, the "debug spew" property, a boolean value, indicates wether or not various "debug messages" will be printed during the execution of
The scanner apparatus API follows.
dfa_state_set -- A set type whose elements are of type dfa_state (see The Automaton Apparatus). dfa_transition_set -- A set type whose elements are of type dfa_transition (see The Automaton Apparatus). scanner_mode_name -- A type which can uniquely identify scanner modes by name. scanner_mode_map -- A type which maps scanner_mode_name onto dfa_state (see The Automaton Apparatus). return_type -- A user-specified type which defines the return type of the Scan method.
automaton -- of a type satisfying the automaton apparatus. states -- of type dfa_state_set. transitions -- of type dfa_transition_set.
Construct (user-specified parameters) -- one-time and each-time initializations; calls automaton.Construct(...), sets the "debug spew" property to false, sets the "scanner mode" to the value specified by start_in_scanner_mode, and calls automaton.ResetForNewInput(). Destruct () -- one-time cleanup operations; user-customizable. IsAtEndOfInput () returns boolean -- simply returns the value of automaton.input_buffer.IsAtEndOfInput(). DebugSpew () returns boolean -- accessor for the "debug spew" property. DebugSpew (boolean debug_spew) -- modifier for the "debug spew" property. ScannerMode () returns scanner_mode_name -- accessor for the "scanner mode" property. ScannerMode (scanner_mode_name) -- modifier for the "scanner mode" property. Scan () returns return_type -- the whole reason this fine mess exists in the first place; runs the automaton until the user-specified rule-handler code causes it to return a value. TODO: more words
 1.5.1
1.5.1