~ (tilde; ASCII value 126). Some terminals are able to print characters in the extended ASCII character set (values between 128 and 255), but for the sake of portability, these "extended" characters will be considered unprintable (and thus require an escape code).
An escaped character consists of a backslash followed by a single character (or formatted sequence in the case of hexadecimal escape characters). For example, a newline is represented as \n while \xF3 represents the ASCII character with numeric value 0xF3. The necessarily escaped characters are:
\a (bell character) \b (backspace) \t (tab) \n (newline) \v (vertical tab) \f (form feed) \r (carriage return) \x# (hexadecimal character literal) -- # represents a string with length of at least one, composed of the hexadecimal digits [0-9a-fA-F] indicating the value of an unsigned hexadecimal integer. If \x is not followed by any hexadecimal characters, it is an error. A hexadecimal character value can technically be any value, but values above \xFF will be truncated. It is preferred to use two hexadecimal characters for the value string, indicative of the value space of the 8-bit value commonly used for a character. Any value, including printable characters which otherwise don't need any escaping, may be represented in this format. It is an error to have a single backslash at the end of a regular expression.
( and ) (parentheses) -- grouping delimiters { and } (curly braces) -- bound delimiters [ and ] (square brackets) -- bracket expression delimiters | (pipe) -- alternation operator ? (question mark) -- indicates 0 or 1 of the previous atom * (asterisk) -- indicates 0 or more of the previous atom + (plus) -- indicates 1 or more of the previous atom . (period) -- matches any character except newline ^ (carat) -- matches the empty string at the beginning of a line $ (dollar sign) -- matches the empty string at the end of a line \ (backslash) -- used for escaping characters All other printable characters (see Necessarily Escaped Characters) have no special meaning, and can be used directly, each accepting itself literally. Any normal character can be escaped, and unless it is one of those listed in Conditionals In BARF Regular Expressions, it will remain unchanged. Non-printable characters will be ignored. For example, a literal newline character within a regular expression will have no effect; it will be as if the newline didn't exist.
Some implementations of regexes have caveats about when certain special characters can be used as normal characters without escaping (such as allowing ) as a normal character in the atom-context of a POSIX regex). This is entirely avoided in BARF for purposes of simplicity and consistency. The rule is that any special character in the applicable context must be escaped to use literally. If this is ever not the case, it is a bug in BARF.
[ and ] (square brackets) -- character class (and bracket expression) delimiters - (hyphen) -- character range operator ^ (carat) -- bracket expression negation operator \ (backslash) -- used for escaping characters
Just like in the atom context, all other printable characters (see Necessarily Escaped Characters) have no special meaning, and can be used directly, each accepting itself literally. In the context of bracket expressions, there are no special escaped characters such as the conditionals described in Conditionals In BARF Regular Expressions. Escaping any character in a bracket expression will cause it to accept itself literally. The necessarily escaped characters such as hexadecimal escape characters, \t (tab), \n (newline), etc, accept themselves as would be expected. Non-printable characters will be ignored.
Some implementations of regexes have caveats about when certain special characters can be used as normal characters without escaping (such as allowing ] if it is the first character, possibly following a ^, as a normal character in the bracket-expression-context of a POSIX regex). This is entirely avoided in BARF for purposes of simplicity and consistency. The rule is that any special character in the applicable context must be escaped to use literally. If this is ever not the case, it is a bug in BARF.
^ and $ (beginning and end of line) generic regex conditionals, BARF provides several others in the form of escaped characters. They are the following.
^ (carat) -- the generic regex special character which accepts the empty string at the beginning of a line $ (dollar sign) -- the generic regex special character which accepts the empty string at the end of a line \b -- accepts the empty string at a word boundary (i.e. the previous character matches [a-zA-Z0-9_] and the next character doesn't, or vice versa) \B -- is the opposite of \b in that it accepts the empty string anywhere that isn't at a word boundary (i.e. both the previous and next characters match [a-zA-Z0-9_] or they both don't) \e -- is equivalent to $ and is included for consistency -- it accepts the empty string at the end of a line \E -- is the opposite of $ and \e in that it accepts the empty string anywhere that isn't the end of a line \l -- is equivalent to ^ and is included for consistency -- it accepts the empty string at the beginning of a line \L -- is the opposite of ^ and \l in that it accepts the empty string anywhere that isn't the beginning of a line \y -- accepts the empty string at the beginning of input (e.g. at the beginning of the input file) \Y -- is the opposite of \y in that it accepts the empty string anywhere that isn't the beginning of input \z -- accepts the empty string at the end of input (e.g. at the end of the input file) \Z -- is the opposite of \z in that it accepts the empty string anywhere that isn't the end of input grep's POSIX regexes).
ostrich\thead
ostrich\x09
Content-Type: text/plain\n\n
\x48\x49\x50\x50\x4F
] is a special character and must be escaped to use in the atom context. ]
\]
\(\)\{\}\[\]\|\?\*\+\.\^\$\\ (hippos|ostriches|dromedaries) are my favorite\.
.{10} ([0-9][0-9])*
([0-9]{2})* [0-9]{2}* ^donkey$
\ldonkey\e
\Ldonkey\E
.|\n
[^0-9]*
[^[:digit:]]*
\(\)\{\}\[\]\|\?\*\+\.\^\$\\ [(){}\[\]|?*+.\^$\\] \[\]-\^
[\[\]\-\^]
LOL!*
L(OL)+!*
L(OL)+!+1+(one)+
All the regular expression facilities of BARF are contained within the Barf::Regex namespace, all the files of which are located in the lib/regex directory.
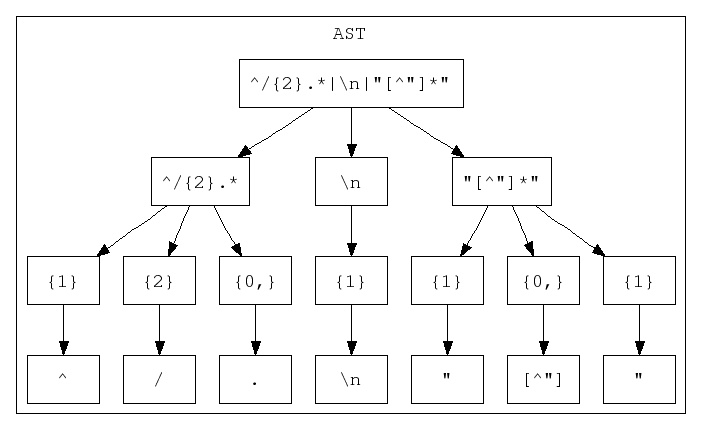
trison. The grammar source file is barf_regex_parser.trison and the AST classes it uses are defined in the files barf_regex_ast.hpp and barf_regex_ast.cpp . Here is the AST resulting from parsing the regex ^/{2}.*|\n|"[^"]*" -- that is, one which accepts C++ style comments which start at the beginning of a line, newlines, or simple C-style string literals without any escaped characters.
If an error is encountered, an exception is thrown -- this is done because the regex facilities in BARF are used as utility functions from within other applications, and to avoid uncontrolled printing of error messages, errors are indicated via exceptions.
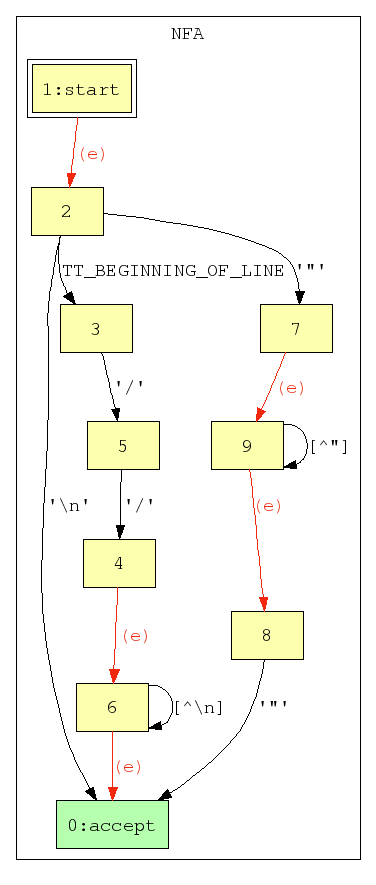
Again, since the regex facilities in BARF are used as utility functions from within other applications, and each application requires a certain amount of customizability in the use of the generated NFAs, the NFA-generating code does not create the NFA's start or accept states -- the client application must provide these. The client application must also take care to keep track of the provided start and accept states, as they are effectively the only point of entry/exit for the NFA.

 1.5.1
1.5.1